Biblioteks-APIer
Overview
Teaching: 45 min
Exercises: 45 minQuestions
Hvordan kan jeg hente ut data fra et API?
Objectives
Kunne kommunisere med et API ved hjelp av
requests-pakkenKunne orientere seg i og trekke ut data fra JSON- og XML-responsobjekter.
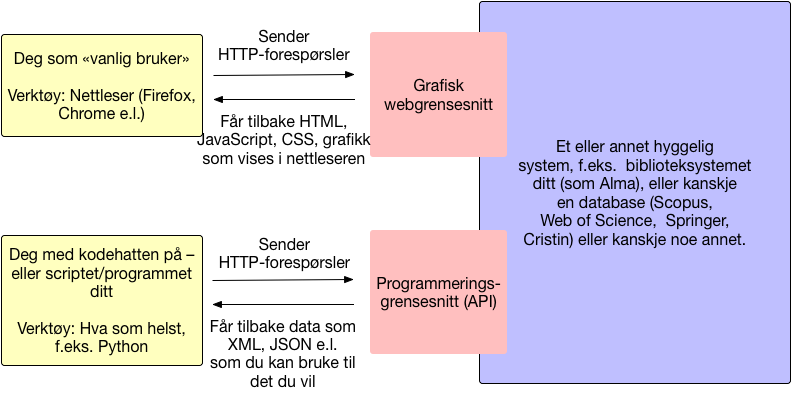
Hva er et API?
Et API (application programming interface eller programmeringsgrensesnitt på godt norsk)
- er et grensesnitt mot et system (f.eks biblioteksystemet ditt) som du kan kommunisere med på en veldefinert måte.
- I praksis skal vi bare se på web-API-er, altså API-er vi snakker med over internett. Det finnes også API-er mellom programmer og andre komponenter på maskinen din.
- Hvis dere leser API-dokumentasjon kommer dere fort over betegnelsen «REST» eller «RESTful». De aller, aller fleste API-er følger disse prinsippene i større eller mindre grad i dag, og det er ikke lenger noe spesielt spennende ved det.
- Kalles også “web services” (webtjenester).
- er typisk langt mer stabilt over tid enn selve systemet bak. I prinsippet kan man bytte ut hele systemet bak og beholde det samme API-et.
- er som regel dokumentert.
- åpner for å enklere kunne automatisere samhandling med et system, og for å trekke ut data fra ulike systemer og kombinere dem.
XML og JSON
Nesten alle API-er returnerer data som XML og/eller JSON.
<xml> |
{json} |
|---|---|
| utviklet i 1997 | utviklet i 2001 |
| minner om html | avledet fra javascript |
| mer komplisert | mindre komplisert |
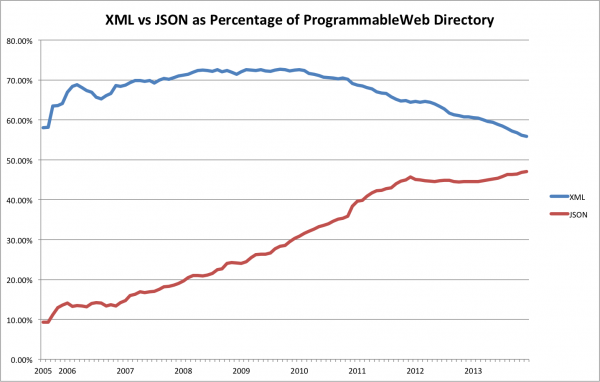
Generelt er JSON enklere å jobbe med, men begge formatene har sine styrker, og i praksis må en forholde seg til begge deler.
HTTP-forespørsler (HTTP-kall) med requests
Vi begynner med å importere requests, som er en Python-pakke (eller et Python-bibliotek)
for å gjøre HTTP-forespørsler (HTTP requests):
import requests
HTTP-forespørsler er ekstremt lite mystisk – det er det vi gjør hver gang vi henter en nettside.
For å illustrere dette kan vi begynne med å hente forsiden til Cristin med requests slik:
requests.get('http://www.cristin.no')
Her kjører vi funksjonen get() fra requests-pakken
(requests-pakken kaller igjen et annet bibliotek som igjen kaller et system-API
osv. osv. Lag på lag med komplisert nettverksfunksjonalitet
som vi heldigvis slipper å forholde oss til – puh!)
Det vi får ut igjen fra get()-funksjonen er et responsobjekt.
For å kunne bruke det videre «putter vi det i en variabel» som vi kaller “response”:
response = requests.get('http://www.cristin.no')
Men hva befinner seg inni dette objektet?
Et objekt er en sekk som kan inneholde forskjellige ting.
Vi kan liste ut hva objektet inneholder med dir()-funksjonen:
dir(response)
Her ser vi f.eks. at det ligger noe som heter “text”.
La oss bruke print()-funksjonen for å se hva som ligger der:
print(response.text)
Ser dere hva dette er? HTML! Det samme som vi ville fått ut hvis vi hadde vist kildekoden til nettsiden i nettleseren vår.
I prinsippet kunne vi prøvd å trekke ut data fra HTML-koden, da er vi inne i det som kalles webscraping. Det er gjerne noe en tyr til for å få ut data fra systemer som ikke tilbyr et API (eller ikke tilbyr dataene du trenger gjennom API-et).
Når vi bruker et API får vi derimot ut data i et maskinvennlig format (typisk JSON eller XML). API-er er nesten alltid dokumenterte (selv om kvaliteten på dokumentasjonen kan variere) og de skal i utgangspunktet ikke endre seg uten forvarsel.
API-er brukes ikke bare for å hente ut data, men også for å endre data. Dette krever en eller annen form for autentisering, f.eks. en hemmelig nøkkel som man legger ved hver forespørsel.
Hente data fra et API
Som eksempel bruker vi Cristin-API-et, hvorfra en kan hente ut norske forskningsresultater. Hvis du googler “api cristin” kommer du til http://api.cristin.no/, som er et ganske ryddig og greit API som vi skal se litt på.
Se også denne Jupyter-notatblokken på Google Colab som vi brukte på Virak 2019 for å vise hvordan vi kan jobbe mot Cristin-API-et med Python.
Noen eksempler
Vi kan f.eks. se på bøker utgitt av en bestemt person med ID 22846. Hvem er det? Prøv og se:
https://api.cristin.no/v2/results?contributor=22846&published_since=2018&category=POPULARBOOK
For å enklere kunne navigere i JSON-strukturen direkte i nettleseren, går det an å installere et nettlesertillegg, som f.eks. JSON Formatter for Chrome.
En liten ulempe med dette API-et er at en må gjøre et nytt oppslag for å få ut navn på forfatterne/bidragsyterne, f.eks.:
https://api.cristin.no/v2/results/1648497/contributors
La oss så bruke requests for å hente inn det samme resultatet med Python:
response = requests.get('https://api.cristin.no/v2/results?contributor=22846&published_since=2010&category=POPULARBOOK')
For å tolke JSON-dataene vi får i retur, kan vi kalle funksjonen json() på respons-objektet, slik:
results = response.json()
For å få oversikt over JSON-strukturen, kan det enkleste være å se på den i Chrome (eller lese dokumentasjonen til API-et). Når vi har funnet ut hva vi er ute etter, f.eks. publiseringsår og tittel, kan vi hente det ut slik:
for result in results:
print(result['year_published'], result['title'])
Her har vi brukt en for-løkke (for loop) for å gå gjennom hvert resultat.
Her er et eksempel på hvordan data fra Cristin-APIet presenteres på UiOs nettsider for å vise de nyeste artiklene fra et bestemt forskningssenter: https://www.med.uio.no/klinmed/forskning/sentre/seraf/publikasjoner/cristin/
Hente bibliografiske data fra API-et til et biblioteksystem
Vi skal se litt på hvordan vi kan hente ut bibliografiske poster fra et SRU-API.
SRU
SRU er en standard søkeprotokoll fra Library of Congress som så godt som alle biblioteksystemer støtter (Det er riktignok ikke alle bibliotek som har åpne SRU-APIer, men mange har det). Et eksempel på en nettside som snakker med SRU-APIer fra mange forskjellige bibliotek er Karlsruher Virtueller Katalog.
Hva betyr det at det er en standard søkeprotokoll? At parametrene er standardiserte, så vi kan bruke de samme parameternavnene uansett hvilket biblioteksystem vi snakker med. Selve søkefeltene (søkeindeksene) er imidlertid ikke standardiserte, så de kan variere fra system til system.
Vi skal bruke Alma som eksempel. Da begynner vi typisk med å google “alma sru”, og kommer vi til API-dokumentasjonen for Almas SRU-tjeneste på https://developers.exlibrisgroup.com/alma/integrations/SRU.
I API-dokumentasjonen kan vi se om det er noen eksempler vi kan prøve rett ut av boksen. Under lenken «searchRetrieveResponse» under overskriften «Examples (in Alma’s Guest sandbox environment)» helt nederst finner vi ett. Trykker vi på lenken gjør nettleseren vår en HTTP-forespørsel og vi får tilbake noe XML-data:
Dataene kommer fra gjestesandkassen, men hvordan får vi det til å virke med våre data? Hvis vi går tilbake til dokumentasjonen ser vi at det står «The base URL for SRU requests is: https://<Alma domain>/view/sru/<institution code>». Alma-domenet kan vi finne fra listen over Alma-instanser.
Vi kan f.eks. prøve med domenet bibsys.alma.exlibrisgroup.com og institusjonskoden 47BIBSYS_NETWORK:
(Prøv evt. gjerne også med verdier fra din egen favorittinstitusjon!)
Nå kan vi prøve å hente den samme URL-en i Python med requests-biblioteket som vi importerte i stad:
response = requests.get('https://bibsys.alma.exlibrisgroup.com/view/sru/47BIBSYS_NETWORK?version=1.2&operation=searchRetrieve&recordSchema=marcxml&query=alma.all_for_ui=history&maximumRecords=3&startRecord=4')
print(response.text)
Dette funker, men det er vanskelig å lese hvor det ene parameteret slutter og det neste starter. Parametrene er det som følger etter spørsmålstegnet, og samlet kalles det query string (spørrestreng). For å gjøre koden ryddigere ønsker vi skille disse ut som variabler:
start = 4
limit = 3
query = 'alma.all_for_ui=history'
response = requests.get('https://bibsys.alma.exlibrisgroup.com/view/sru/47BIBSYS_NETWORK', params={
'version': '1.2',
'operation': 'searchRetrieve',
'startRecord': start,
'maximumRecords': limit,
'query': query,
})
print(response.text)
Resultatet fra å kjøre denne koden er nøyaktig det samme som resultatet fra å kjøre det forrige eksempelet, men nå har vi en kodesnutt som er lettere å bearbeide videre – og det er bra! For å gjøre det enda lettere å bruke denne kodesnutten vil vi gjøre den om til en funksjon.
Jupyter-tips: Marker flere linjer tekst og trykk Tab for å indentere alle linjene samtidig.
def sru_search_request(query, start=1, limit=50):
response = requests.get('https://bibsys.alma.exlibrisgroup.com/view/sru/47BIBSYS_NETWORK', params={
'version': '1.2',
'operation': 'searchRetrieve',
'startRecord': start,
'maximumRecords': limit,
'query': query,
})
return response
Nå kan vi gjøre et nytt søk med bare én linje kode!
response = sru_search_request('alma.creator="hurum, jørn"')
print(response.text)
Hjelp, hva gjør jeg med all denne XML-teksten?
Neste spørsmål er hvordan skal vi navigere i dette havet av XML-tekst som vi får tilbake fra API-et.
Dette er biblioteksløyd, så vi skal prøve et nytt verktøy, nemlig en Python-pakke som parser XML (parse betyr å tolke teksten og gjøre den om til et objekt vi kan jobbe med).
Det finnes mange forskjellige slike pakker (google “python xml”), og de har ulike fordeler og ulemper.
I dag skal vi bruke et kalt xmltodict, som gjør XML-teksten om til en såkalt dictionary (ordliste)
eller dict, som gjør at vi kan jobbe med responsen på samme måte som vi ville gjort fra et JSON-API.
Apropos xmltodict, hva er egentlig en
dict?En ordbok / dictionary (dict) er en sentral datatype i Python (i andre programmeringsspråk ofte kalt hashmap, associated array e.a.). En dict er et enkelt objekt som du kan putte ulike ting oppi, og der hvert ting har en etikett, som du kan bruke til å enkelt finne tingen igjen.
For å finne ut strukturen til XML-filen kan det enkleste noen ganger være å forhåndsvise den i nettleseren din, f.eks. Chrome. Digresjon: Det finnes selvfølgelig en pakke du kan bruke for å åpne nettleseren din også:
import webbrowser
webbrowser.open(response.url)
Når vi ser på XML-en ser vi at toppnivået heter “searchRetrieveResponse”. Deretter følger “records” og “record”. Denne noden er det flere av, så det er en liste. Hver “record”-node har en “recordData”-node som igjen har en “record”-node.

La oss prøve å navigere i XML-strukturen med Python.
Først må vi importere xmltodict:
import xmltodict
Vi ønsker å lage en liste som inneholder alle MARC-postene, men ikke alt det som ligger rundt. Det kan vi gjøre slik:
xml = xmltodict.parse(response.text, force_list=['record', 'datafield', 'subfield'])
records = []
for rec in xml['searchRetrieveResponse']['records']['record']:
records.append(rec['recordData']['record'][0])
I parentes: Hvis vi er nysgjerrige på hvor mange poster vi har i listen vår kan vi sjekke med len()-funksjonen:
len(records)
Oppgave 1: Bygge om
sru_search_request-funksjonen til å returnere en liste med MARC-posterLitt tidligere laget vi funksjonen
sru_search_request, som utfører et søk og returerner et responsobjekt. Men vi vil heller at den heller skal returnere en liste med MARC-poster. Kan du utvide funksjonen slik at den gjør det? Bruk koden over. For å unngå forvirring er det lurt å kopiere den gamle funksjonen inn i en ny celle og gi den et nytt navn:sru_search_request2.Løsning
def sru_search_request2(query, start=1, limit=50): response = requests.get('https://bibsys.alma.exlibrisgroup.com/view/sru/47BIBSYS_NETWORK', params={ 'version': '1.2', 'operation': 'searchRetrieve', 'startRecord': start, 'maximumRecords': limit, 'query': query, }) xml = xmltodict.parse(response.text, force_list=['record', 'datafield', 'subfield']) records = [] for rec in xml['searchRetrieveResponse']['records']['record']: records.append(rec['recordData']['record'][0]) return records
Oppgave 2: Hente ut leader fra den første MARC-posten
Vi har
records, som er en liste. Du kan hente ut det første elementet fra listen (altså den første MARC-posten) medrecords[0]. Se på strukturen til XML-filen, enten i nettleseren din eller figuren over.
- (a) Klarer du å hente ut verdien til feltet leader for den første posten?
- (b) Kan du lage en
for-løkke og brukeLøsning
(a)
records[0]['leader'](b)
for record in records: print(record['leader'])
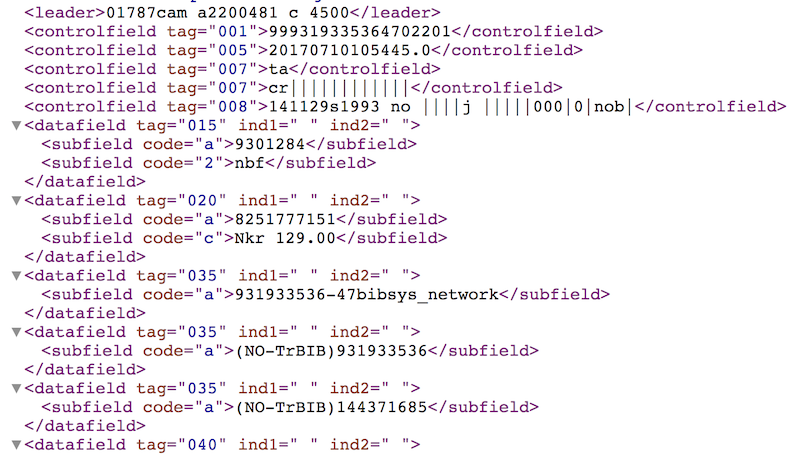
Oppgave 3: Fyll inn det som mangler (__)
Kopier kodesnutten under til din notebook. Prøv å finn ut hva du må erstatte “__” med for å få koden til å virke (det er ikke det samme begge stedene). Hva gjør koden?
for rec in records: for field in ______['datafield']: if field['@tag'] == '245': for subfield in ______['subfield']: if ______['@code'] == 'a': print(subfield['#text'])Løsning
for rec in records: for field in rec['datafield']: if field['@tag'] == '245': for subfield in field['subfield']: if subfield['@code'] == 'a': print(subfield['#text'])
Skrive ut tittel og Dewey-nummer:
for rec in records:
# Det kan være lurt å tømme variablene først
tittel = ''
dewey_numre = []
for field in rec['datafield']:
if field['@tag'] == '245':
for subfield in field['subfield']:
if subfield['@code'] == 'a':
tittel = subfield['#text']
if field['@tag'] == '082':
for subfield in field['subfield']:
if subfield['@code'] == 'a':
dewey_numre.append(subfield['#text'])
print(tittel, dewey_numre)
Hvis vi bare vil ha unike numre kan vi gjøre om listen til et sett: set(dewey_numre)
Tenk om det fantes et API der vi kunne sende inn et Dewey-nummer og få ut klassebetegnelsen fra norsk Webdewey. La oss prøve det.
for rec in records:
# Det kan være lurt å tømme variablene først
tittel = ''
dewey_numre = []
for field in rec['datafield']:
if field['@tag'] == '245':
for subfield in field['subfield']:
if subfield['@code'] == 'a':
tittel = subfield['#text']
if field['@tag'] == '082':
for subfield in field['subfield']:
if subfield['@code'] == 'a':
dewey_numre.append(subfield['#text'])
print('Tittel:' + tittel)
for dewey_nummer in set(dewey_numre):
dewey_response = requests.get('https://ub-www01.uio.no/microservices/dewey_heading.php', params={
'number': dewey_nummer,
})
print(' ' + dewey_nummer + ' ' + dewey_response.text)
Key Points
API-er (programmeringsgrensesnitt) er en annen inngang til et system enn den du gjerne bruker til vanlig.
API-er kommuniserer over HTTP og du kan bruke et hvilket som helst programmeringsspråk for å snakke med dem.
API-er utveksler data i programmeringsvennlige formater, typisk JSON og/eller XML.
API-er er vanligvis stabile (endrer seg ikke uten forvarsel), i motsetning til vanlige nettsider, som typisk ikke er det. som endrer seg uten forvarsel.
API-er er vanligvis dokumenterte, men det kan være mye ny terminologi å forholde seg til.